Python으로 달러 환율과 달러 인덱스 데이터 다루기
들어가며
아래 포스팅의 이유로 달러 인덱스 선물을 달러 선물 대신에 쓸 수 있는지 검증이 필요하게 되었다.
python과 통계, 수학을 이용하여 이 것이 가능한 지 알아보자.
(코드 전문은 Google Colab에서 확인할 수 있습니다.)
코드 주요 부분 설명
usdkrw = fdr.DataReader('USD/KRW', '2021-12-01')['Close']
dxy = fdr.DataReader('DX-Y.NYB', '2021-12-01')['Close']
1년간의 환율, 달러인덱스 데이터를 불러오는 부분.
직접 크롤링하거나 증권사 API 써야하나 싶었는데 finance-datareader라는 편리한 패키지가 있더라.
데이터라는 건 다다익선이지만, 증시는 또 너무 옛날이면 의미가 없어서 적당하게 최근 1년치로 정했다.
### Series to Dataframe
merged_df = pd.concat([usdkrw, dxy], axis=1)
merged_df.columns=['USD/KRW', 'Dollar index']
### Interpolate datetime index
merged_reindexed_df = merged_df.reindex(
pd.date_range(
start=merged_df.index.min(),
end=merged_df.index.max(),
freq='1D'
)
)
### Interpolate values
merged_reindexed_interp_df = merged_reindexed_df.interpolate()
데이터의 안정성을 위해서, 끊기는 구간과 결측치가 없도록 interpolation 해주는 과정이다.
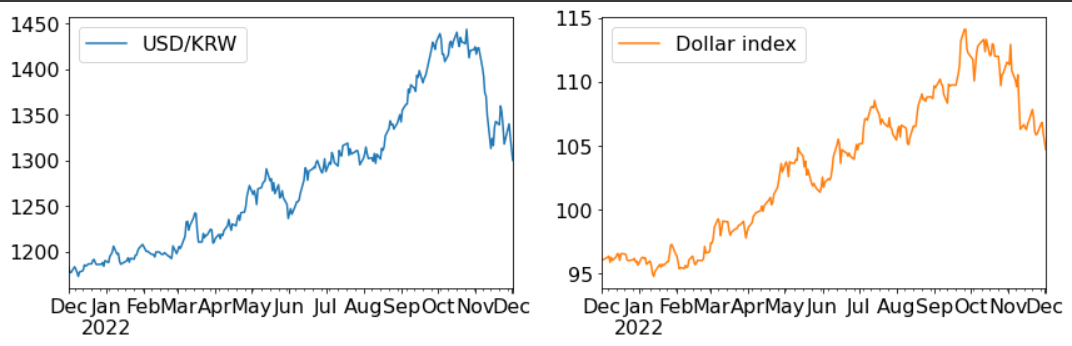
[정제 후의 각 지표 plot. 시각적으로는 두 지표가 매우 유사해보인다]
merged_reindexed_interp_df.corr(method='pearson')
환율과 달러 인덱스가 비슷한 흐름을 띄는 지를 알아보기 위해 상관관계 분석을 실시한다.
pearson correlation 메소드를 사용하였다.
결과는 0.972424의 r 값을 가짐으로서, 매우X100000 강한 양의 상관관계를 가지는 것을 알 수 있다.
merged_reindexed_interp_df.plot.scatter(x='Dollar index', y='USD/KRW')
usdkrw_sr = merged_reindexed_interp_df['USD/KRW']
dxy_sr = merged_reindexed_interp_df['Dollar index']
usdkrw_dxy_reg = np.polyfit(dxy_sr, usdkrw_sr, 1)
sns.lineplot(
x=np.unique(dxy_sr),
y=np.poly1d(usdkrw_dxy_reg)(np.unique(dxy_sr)),
color='r',
alpha=0.8,
linewidth=3
)
데이터의 관계가 선형(linear)인지를 알아보기 위해, simple linear regression 라인도 피팅시켜 본다.
correlation을 사용할 때는, 그냥 r value만 보고 끝낼 것이 아니라, 이런 검증 작업 혹은 p value 같은 것도 확인해줘야 더 신뢰도가 높다.
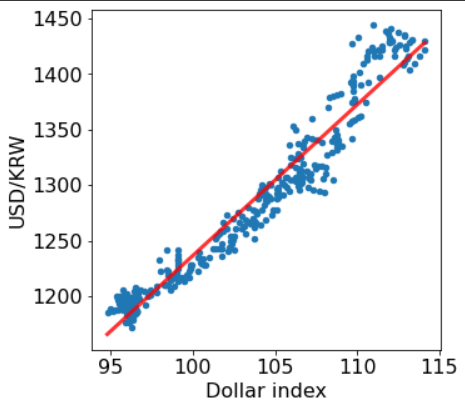
많은 사람들이 correlation analysis 과정에서 regression을 종종 사용하기 때문에 그러려니 하고 넘어갈 수도 있지만, 사실 이 것을 사용한 것은 꽤나 그럴듯한 이유가 더 있다.
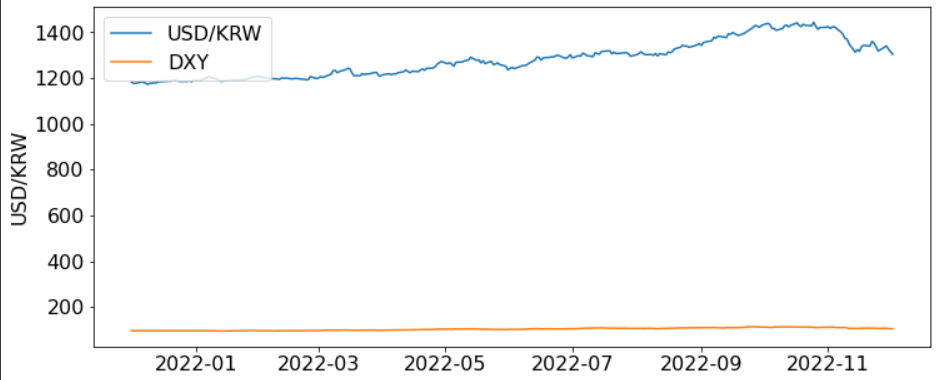
[두 지표를 그냥 같이 표시한 모습. 스케일이 많이 달라서 비교하기 힘들다]
어떤 지표를 다른 지표 대신 쓸 수 있는 지 보려면 두 지표를 겹쳐봤을 때의 경향이 눈으로 봐도 차이가 적어야 한다.
지금 같은 경우는 스케일이 너무 달라서 비교하기가 어렵지만, 앞서 구한 regression 값으로 스케일링이 가능하다.
plt.figure()
sns.lineplot(
x=merged_reindexed_interp_df.index,
y=merged_reindexed_interp_df['USD/KRW'],
label='USD/KRW'
)
sns.lineplot(
x=merged_reindexed_interp_df.index,
y=merged_reindexed_interp_df['Dollar index']*usdkrw_dxy_reg[0] + usdkrw_dxy_reg[1],
label='rescaled_DXY'
)
plt.legend(loc='upper left')
plt.show()
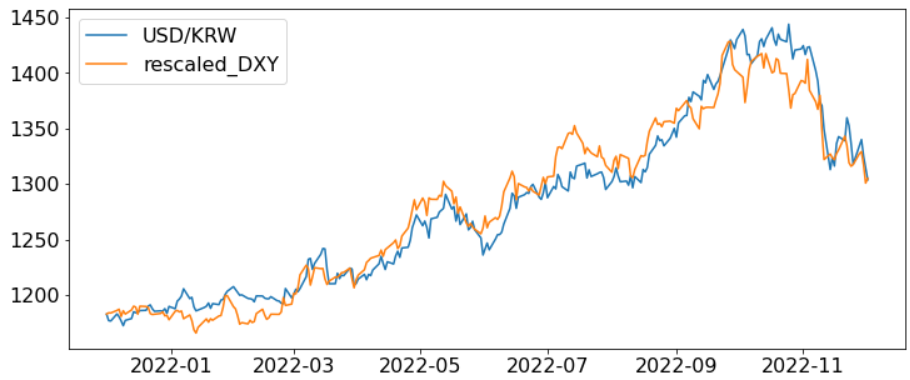
[작성한 코드에 따라 달러 인덱스의 스케일과 Y 절편이 환율에 맞춰서 조정된 모습.]
앞서 구한 regression 값으로 달러 인덱스 값을 스케일링하는 코드이다.
우리가 적용한 것은 고작 선형 연산이니 [$ax+b\ (a, b는\ 상수)$], 이렇게만 보면 달러 인덱스가 환율을 아주 쉽게 대체할 수 있는 것처럼 보였다.
하지만 여기서 가장 큰 문제는 b다.
스케일링 상수 a의 경우, 달러 인덱스 선물을 더 혹은 덜 사는 식으로 실제로 컨트롤 가능하다.
만약 a가 2일 경우, 구매하고자 하는 환율 선물상품의 2배만큼 사면 된다.
만약 a가 1/2일 경우, 구매하고자 하는 환율 선물상품의 1/2배만큼 사면 된다.
그런데 y절편은 적용할 방법이 없다. 따라서 다른 방법을 찾아야 한다.
$y=ax+b$ 형태가 아닌 $y=ax$ 형태로 만들자
그러기 위해선 y축이 0부터 시작하는 데이터로 바꿔야 하는데, 이는 기준 시점을 잡고 percentage 그래프로 표현하면 가능하다.
usdkrw_volatility_array = (merged_reindexed_interp_df['USD/KRW'].values / merged_reindexed_interp_df['USD/KRW'].values[0]) - 1
dxy_volatility_array = (merged_reindexed_interp_df['Dollar index'].values / merged_reindexed_interp_df['Dollar index'].values[0]) - 1
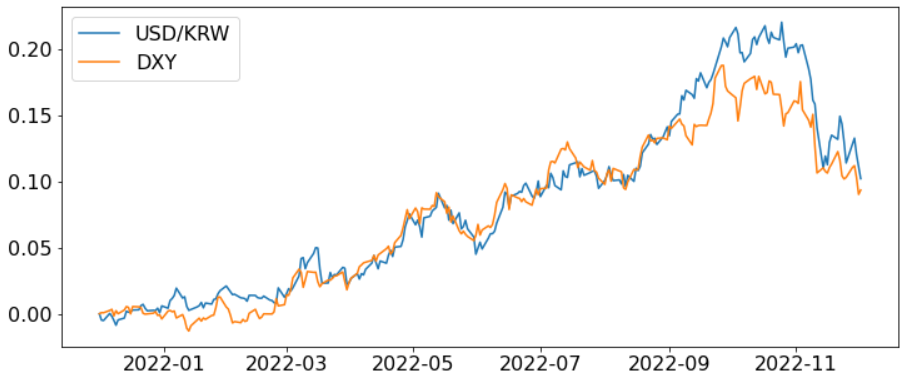
[y축을 2022-12-01 기준 % 스케일로 바꿨을 때 플롯]
따로 rescale 안해도 어느 정도는 맞지만, 최근 환율이 급상승 했을 때 비율이 많이 어긋나는 것을 확인할 수 있다.
이러한 상황을 고려해서도 어느 정도는 스케일을 맞춰줄 필요가 있어보인다.
usdkrw_smooth_array = scipy.ndimage.gaussian_filter1d(usdkrw_volatility_array, 1, axis=- 1, order=0, output=None, mode='reflect', cval=0.0, truncate=4.0)
dxy_smooth_array = scipy.ndimage.gaussian_filter1d(dxy_volatility_array, 1, axis=- 1, order=0, output=None, mode='reflect', cval=0.0, truncate=4.0)
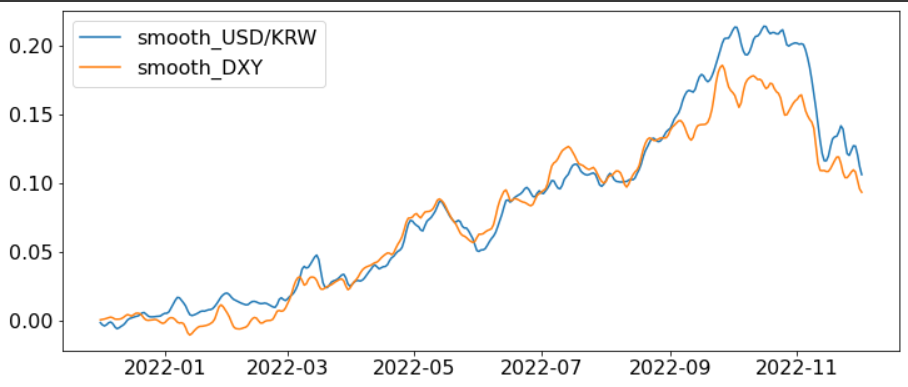
지표 특성 상 튀는 값이 종종 있는데, 이는 OLS 기반 추정에 좋지 않으니 약하게 smoothing을 적용한다.
이는 평균적으로는 안정적이게 되겠지만, 디테일하게는 약간의 오차를 감내하게 된다.
나의 경우는 이렇게 만든 결과를 하루이틀 쓰고 버릴 것이 아니라 최소 2주는 유지하게 될 것이므로 오히려 장기적으로 안정적인 것이 좋다.
이런 것이 매우 중요하다. “그냥 다들 smoothing 한 번씩 돌리길래…”, “smoothing 하니까 MSE 좀 더 낮아지길래…“로 끝내는 것이 아닌, 현실적으로 내가 적용하고자 하는 부분에 어떤 영향을 줄 지 생각해보는 것.
lr = LinearRegression()
lr.fit(dxy_smooth_array[...,np.newaxis], usdkrw_smooth_array)
w = lr.coef_[0] # 결과 약 1.1062
plt.figure()
sns.lineplot(
x=merged_reindexed_interp_df.index,
y=usdkrw_smooth_array,
label='USD/KRW'
)
sns.lineplot(
x=merged_reindexed_interp_df.index,
y=(dxy_smooth_array*w),
label='rescaled_DXY'
)
plt.legend(loc='upper left')
plt.show()
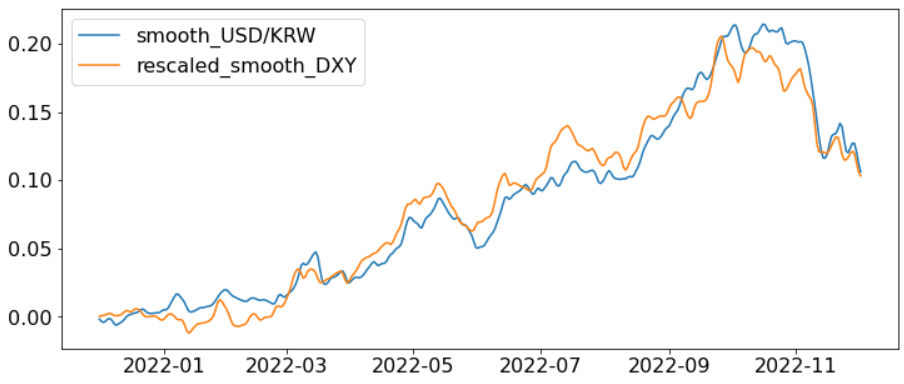
[계산된 w를 기반으로 스케일링한 DXY는 확실히 이전에 비해 달러 환율 지표에 잘 맞아보인다.]
scikit-learn의 linear regression을 이용하여 계수 w를 구하고, 이를 DXY에 곱한다.
중간중간 갭이 좀 생기지만 이 정도면 만족한다.
결론적으로 달러 인덱스 선물을 달러 선물 대신 사용하려면 달러 인덱스 선물 + 10%만큼 더 구매하는 식으로 하면 될 듯.
정리
python으로 금융 지표를 쉽게 불러오고 시각화를 해 보았다.
다양한 pandas 함수로 지표들을 쉽게 정리하고 결측치를 보완하였다.
pearson correlation을 통해 서로 다른 지표의 상관성을 알아보았다.
linear regression을 통해 어떤 지표가 다른 지표를 보완할 수 있는 지를 알아보았다.
꽤나 유사하게 환율의 추세를 따라가기는 하나, 완벽하게 환율 지표를 대체하기는 힘들 듯 하다.
장기적으로 쓰고자하는 목적이면 큰 문제가 되지 않을 듯 하다.
달러 선물 대신 달러 인덱스 선물을 써야한다면, 달러 인덱스 선물을 10%정도 더 많이 구매하면 된다.
마치며
단순히 python 코드만 보려고 찾아오신 분이 있다면 금융 쪽 이야기에 조금 당황하셨을 수도 있다.
나도 당황했다;; 금융 관련된 이야기는 다른 포스팅에 쓰고 이 쪽에서는 되도록이면 코딩 관련된 이야기만 쓰려고 했는데… 코드를 작성하는 목적을 제외하고 코드설명을 한다는 것이 나에게는 불가능했다 ㅠㅠ
그리고 그냥 간단하게 데이터 불러와서 correlation 때리면 끝날 줄 알았던 작업이 선형대수학의 최소제곱법까지 끌어다 쓰게 될 줄은 몰랐다;;
그 당시 더 열심히 공부했다면 이 정도로 오래 끌지는 않았을까… 모르겠다. 그 당시 조금이라도 했으니까 지금 이렇게 풀어갈 수 있었던 것이라고 좋은 쪽으로 생각해야지.